

.svg)

.svg)
.svg)
.svg)
.svg)
.svg)
If a page is not indexed, it cannot rank. It does not matter how strong the content is or how well it is optimized. Without indexation, it simply does not exist in search results.
In modern SEO, the process follows three core steps: crawl, index, and rank. First, search engines discover pages through crawling. Next, they decide whether those pages deserve a place in their index. Only after that can a page compete for rankings. Indexing is the foundation of online visibility.
For large websites, this is where problems begin. Studies show that only about 37% of crawled URLs actually get indexed by Google. That means most discovered pages never make it into search results. Another widely cited analysis by Ahrefs found that only around 14% of newly published pages are indexed within a week, and the average indexing time is roughly 27 days. For agencies managing ecommerce platforms, marketplaces, SaaS portals, or enterprise sites with tens of thousands of URLs, these numbers matter.
Large-scale indexing issues create a serious business impact:
- Valuable pages remain invisible
- Organic traffic drops without a clear warning
- Marketing budgets are wasted on content that never ranks
- Clients question performance and ROI
As websites grow, indexing challenges grow with them. Crawl budget becomes stretched. Duplicate content increases. Technical mistakes multiply. Internal teams often struggle to diagnose the root causes across thousands of URLs.
This is where white label SEO services step in. By combining advanced diagnostics, structured workflows, and scalable technical processes, they help agencies resolve complex indexation problems without expanding internal teams. Instead of reacting to traffic losses, agencies can proactively manage index health at scale.
Before we look at how solutions work, it is important to understand why these issues happen in the first place.
Why Large-Scale Indexing Issues Happen?
A. Crawl Budget Constraints and Crawl Inefficiencies
Crawl budget refers to the number of pages a search engine bot will crawl on a website within a specific period. Google does not share exact numbers, but it has confirmed that very large websites can face crawl limitations. When a site grows into the hundreds of thousands or millions of URLs, efficient crawling becomes critical.
On small websites, crawl budget rarely becomes a serious concern. Search engines can easily discover and revisit every important page. However, once a site scales, inefficiencies multiply. Bots must decide where to spend their time. If too many low-value URLs exist, important pages may not be crawled frequently enough.
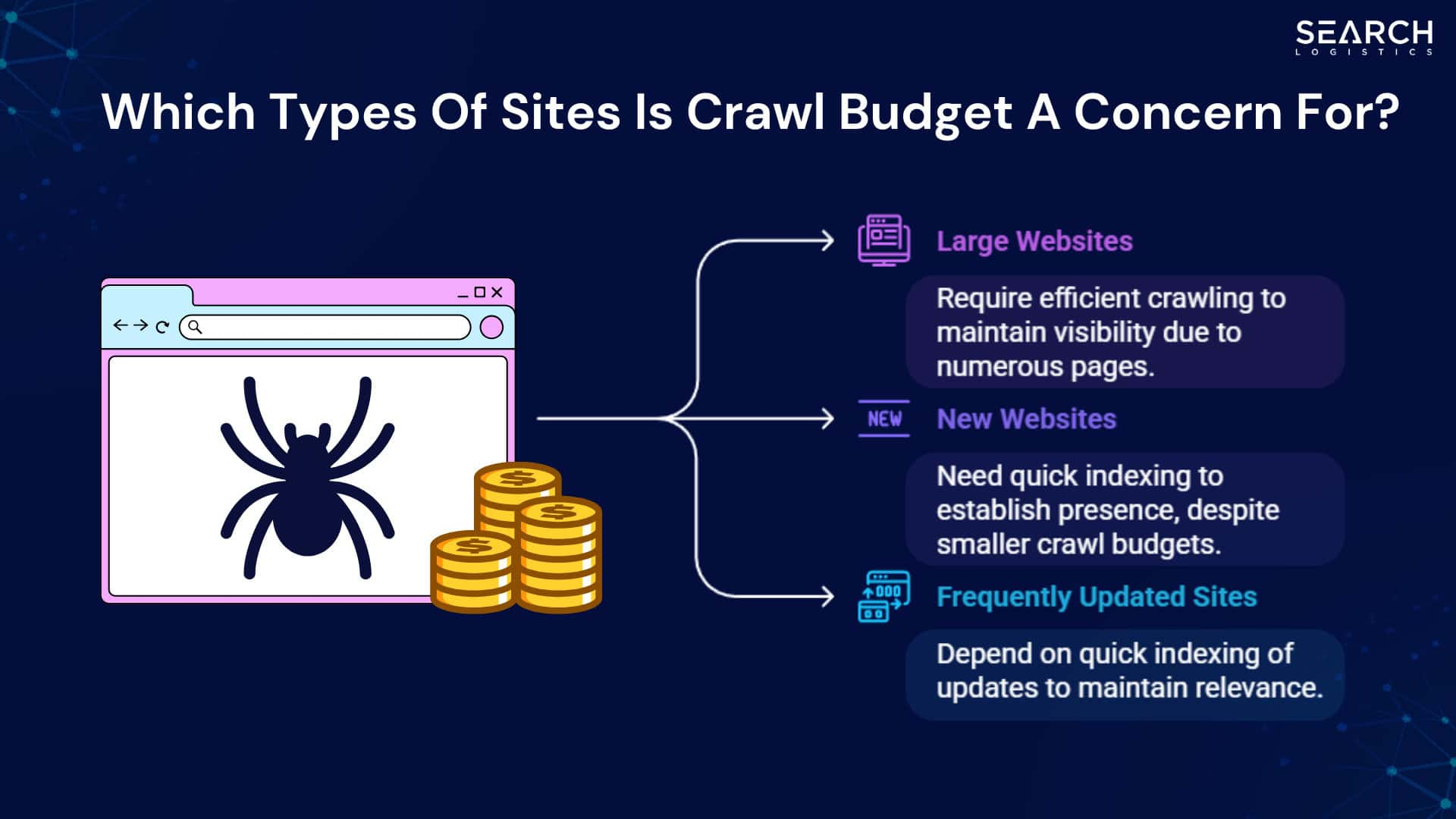
Images Source: Search Logistics
Crawl waste is one of the biggest drivers of indexing issues on enterprise websites. Common sources include:
- Duplicate URLs created by filters and sorting parameters
- Session IDs that generate countless variations of the same page
- Faceted navigation systems that produce near-identical combinations
- Low-value category or tag pages
- Paginated archives without proper canonical handling
- Printer-friendly or tracking versions of core URLs
Industry research across large eCommerce and marketplace sites suggests that 30 to 40 percent of crawl activity can be spent on duplicate or thin pages. In extreme cases, that percentage can be even higher. When bots repeatedly crawl redundant URLs, they delay the discovery of newly published or updated high-priority content.
The business impact is clear. Product launches may not appear in search quickly. High-margin service pages may remain undiscovered. Seasonal campaigns may miss their window.
Over time, inefficient crawling also sends quality signals. If a large portion of a website appears repetitive or low-value, search engines may reduce crawl frequency overall. That creates a cycle where less important pages are revisited, slowing index updates.
The result is straightforward: priority pages fail to get indexed or refreshed.
Without log file analysis and structured crawl audits, agencies cannot see how bots are truly interacting with a site. That is why technical crawl diagnostics are always the first step in resolving large-scale indexation problems.
B. Technical Barriers Preventing Indexing
Even when the crawl budget is healthy, technical misconfigurations can block pages from entering the index.
Some of these errors are small but widespread. A single misplaced directive in a template can affect thousands of URLs instantly. On enterprise sites, that risk increases because multiple teams often manage different sections of the platform.
Common technical barriers include:
- Robots.txt rules that unintentionally block entire folders
- Noindex tags applied to templates that should be indexable
- Canonical tags pointing to incorrect or outdated URLs
- Conflicts between HTTP, HTTPS, www, and non-www versions
- Redirect chains and loops that interrupt crawler paths
- Incorrect hreflang implementation on international sites
Google Search Console often reports large numbers of excluded pages under categories such as “Crawled – currently not indexed,” “Duplicate without user-selected canonical,” or “Blocked by robots.txt.” For agencies overseeing several large accounts, manually reviewing these patterns becomes overwhelming without standardized processes.
Orphan pages are another frequent issue. These pages exist but have no internal links directing users or bots toward them. Even if included in an XML sitemap, weak internal linking reduces their importance in the eyes of search engines. Bots rely heavily on internal pathways to discover and prioritize content.
Index bloat adds another layer of complexity. When too many low-quality or redundant pages get indexed, overall crawl efficiency suffers. Search engines may begin to question the value of the site. In some cases, they scale back crawling because the ratio of high-quality to low-quality content appears unbalanced.

For agencies, diagnosing these problems across thousands of URLs is not simple. Issues often overlap. A page may be technically accessible but still excluded due to canonical conflicts or duplication signals. Identifying patterns at scale requires structured tools and consistent review processes.
Finding the issue is only half the work. Implementing fixes across development environments, CMS systems, and content workflows requires coordination and a clear plan.
C. Content and Quality Challenges
Indexing decisions are not purely based on technical accessibility. Google evaluates whether a page deserves a place in its index. If it determines that the content lacks value, it may choose not to include it.
Thin content remains one of the most common reasons for exclusion. eCommerce sites often rely on short manufacturer descriptions. Location pages may differ only by city name. Automatically generated content can create thousands of low-depth URLs. These pages are crawlable, but they may not meet quality thresholds.
Duplicate content compounds the issue. Large product catalogs frequently reuse similar descriptions across multiple variations. Service pages may follow identical structures with minimal differentiation. When search engines detect high similarity, they select one version as canonical and ignore the rest.
As of 2025, Google continues to emphasize E-E-A-T principles, which stand for Experience, Expertise, Authoritativeness, and Trustworthiness. While these concepts are often discussed in ranking conversations, they also influence indexing decisions. Pages lacking credible signals, clear authorship, or meaningful depth may struggle to enter the index in competitive industries such as health, finance, and legal services.
Content quality issues can be harder to detect than technical errors. A URL may appear perfectly optimized from a structural perspective, yet still fail to index because it does not offer unique value. In Search Console, these cases often appear under “Crawled – currently not indexed,” which can be misleading without deeper analysis.
For agencies managing multiple large sites, distinguishing between technical exclusions and quality-driven exclusions requires detailed inspection. Without careful review, teams may attempt technical fixes for what is actually a content problem.
These layered challenges explain why indexing at scale is complex. Crawl inefficiencies, technical barriers, and content limitations often interact. Solving one without addressing the others rarely produces lasting results.
Understanding this complexity sets the foundation for how white label SEO services approach indexing management in a structured and scalable way.
How White Label SEO Services Diagnose and Fix Indexing Issues?
A. Scalable Diagnostic Frameworks
White label SEO teams rely on structured, repeatable frameworks to uncover indexing problems quickly and accurately.
1. Technical SEO Audits and Crawl Analysis
Using tools such as Screaming Frog, Sitebulb, and log file analyzers, specialists simulate how search engines crawl a website. These audits reveal:
- Blocked resources
- Broken internal links
- Incorrect canonicals
- Duplicate content clusters
- Redirect loops
Log file analysis provides deeper insight. It shows how bots actually behave, not just how the site is structured. Agencies often discover that search engines spend excessive time on low-priority pages.
In many cases, crawl errors can be reduced dramatically after structured remediation. For example, large eCommerce sites have reduced error counts from thousands to under a hundred through prioritized fixes.
The outcome is a clear action plan for developers and content teams.
2. Search Console Coverage and URL Inspection Analysis
Google Search Console offers direct insight into index coverage. White label SEO services providers analyze:
- Excluded URLs by reason
- Crawled but not indexed patterns
- Discovered but not indexed pages
- Duplicate canonical conflicts
Instead of reviewing individual URLs manually, they identify patterns across entire sections. This allows agencies to solve problems in bulk rather than page by page.
Once diagnostics are complete, the focus shifts to targeted resolution.
B. Root-Cause Resolution Strategies
1. Robots, Noindex, and Canonical Corrections
Many indexing problems stem from simple configuration errors. Cleaning up robots directives, removing unintended noindex tags, and correcting canonical signals often leads to rapid improvement in coverage.
2. XML Sitemap Optimization
Sitemaps should contain only valuable, index-worthy pages. White label SEO teams restructure sitemaps to:
- Exclude duplicate or thin URLs
- Highlight priority sections
- Ensure accurate last-modified dates
This improves discovery efficiency and signals importance to search engines.
3. Internal Linking Engineering
Internal linking strongly influences crawl depth and indexation. By restructuring navigation and contextual links, teams help search engines reach important pages more easily.
Tactics include:
- Adding links to orphan pages
- Strengthening category hierarchies
- Implementing breadcrumb improvements
- Creating topic clusters

4. Index Bloat Reduction
Removing or consolidating thin pages increases overall site quality. This may involve:
- Merging similar content
- Deleting low-value URLs
- Blocking parameter variations
- Using canonical tags strategically
Improving crawl efficiency often leads to better indexing of high-priority pages.
5. JavaScript and Rendering Improvements
Modern websites rely heavily on JavaScript. If content is not properly rendered, bots may struggle to index it.
White label SEO specialists may recommend server-side rendering or improved structured data implementation to enhance indexability.
But fixing issues once is not enough. Ongoing monitoring is critical.
C. Continuous Monitoring and Reporting
Large-scale indexing requires constant oversight. White label SEO services implement automated tracking using Search Console APIs and enterprise dashboards.
Agencies receive:
- Index coverage trend reports
- Crawl error updates
- Alerts for sudden exclusions
- Performance correlation data
Success metrics typically include:
- Percentage increase in indexed pages
- Reduction in crawl errors
- Organic traffic recovery
For example, case data from industry reports shows index coverage improving from 40% to over 90% after systematic remediation, with organic traffic increasing by more than 150 percent in some scenarios.
Consistent reporting ensures transparency and keeps clients informed without overwhelming them with technical detail.
DashClicks’ White Label SEO Services: A Scalable Indexing Solution for Agencies
DashClicks provides structured white label SEO services built specifically for agencies managing multiple client accounts. Their approach focuses on scalable technical audits, crawl diagnostics, and systematic index coverage improvements.
For large and complex websites, DashClicks conducts detailed technical evaluations using Google Search Console insights and advanced crawling tools. These audits identify crawl inefficiencies, indexing exclusions, sitemap inconsistencies, and canonical conflicts. Instead of surface-level checks, the process uncovers root causes that affect thousands of URLs.
Once issues are identified, DashClicks supports resolution across:
- Robots.txt corrections
- Noindex and canonical cleanups
- Sitemap restructuring
- Internal linking improvements
- Index bloat reduction
The process does not stop at implementation. Ongoing monitoring ensures that indexing health remains stable as sites grow. Agencies receive white-labeled reports aligned with their branding, making it easier to communicate progress to clients.
This structured execution model allows agencies to handle enterprise-level indexing challenges without hiring additional technical staff. It brings consistency across multiple accounts while maintaining quality control.
Conclusion
Large-scale indexing issues can quietly undermine even the strongest SEO strategy. When important pages remain excluded, visibility drops. Traffic declines. ROI weakens.
Better index coverage leads to stronger visibility. Stronger visibility leads to more traffic. More traffic creates measurable business growth.
White label SEO services make this possible through structured audits, prioritized fixes, and continuous monitoring. Instead of guessing why pages are not ranking, agencies gain clarity and control over index health at scale.
If your agency manages growing websites and needs reliable support for complex indexing challenges, it may be time to strengthen your technical foundation.


.svg)




.svg)
.svg)
.svg)
.svg)
.svg)