

.svg)

.svg)
.svg)
.svg)
.svg)
.svg)
Crawling and indexing your web pages is a critical component of any SEO strategy.
To achieve these goals, marketing specialists utilized a free tool known as Google Search Console. This application monitors your website to track health errors that directly impact performance and search engine rankings.
When analyzing your website, you may encounter something known as an index coverage issue.
This article will explain what indexing issues are, why they occur, and what you can do to fix Google index coverage issues moving forward.
What Are Index Coverage Issues?
To better explain an index coverage issue, let's first explore how the indexing process works.
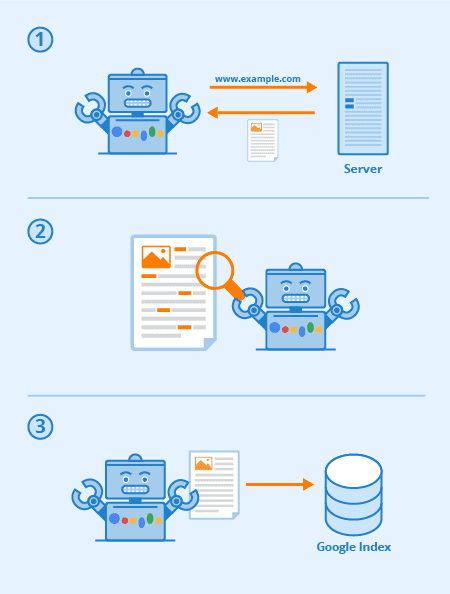
To manually submit your site to Google Search Console, you will need something known as an XML sitemap. This site map lists all of the pages present on your website along with their corresponding URLs.
Otherwise, Googlebot will periodically attempt to crawl your site by following links on and off of the domain.
Crawling is the process Googlebot uses to discover a URL and read the content on the page. Once it reaches the URL, it begins the process of indexing the data.
Indexing is the process in which Googlebot attempts to understand the content. It does this by checking for keywords, analyzing headlines, reading content, and following internal and outbound links. The better it can understand a page, the more accurately it can “grade” a URL for search rankings.
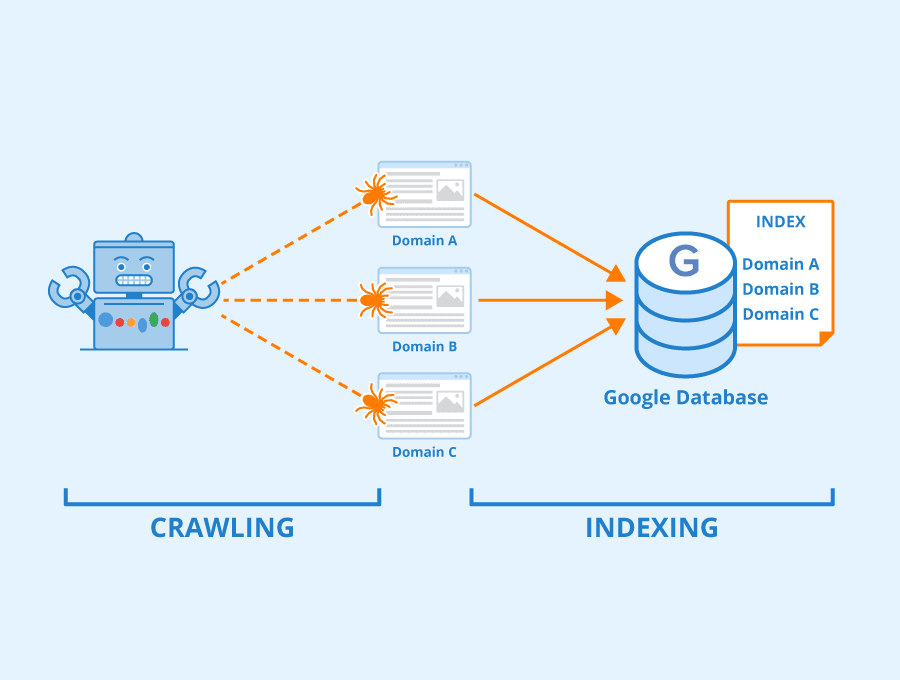
With this information in mind, let's answer the initial question.
An index coverage issue happens if something prevents Google from properly crawling and indexing a URL.
You can identify an index coverage issue by checking your Google Search Console Index Coverage Report for one of four status notifications.
The Four Index Status Codes and How to Fix Them
When the indexing process is complete, each URL will feature an index coverage status. You can find a full list of these statuses courtesy of Google here.
Valid
Ideally, all of your URLs will have the “Valid” status.
This means that Googlebot was able to successfully index the webpage without any notable issues.
You will only receive a notification if you did not include this URL in your sitemap. If you intend to index a page, always be sure to properly list it within the XML file.
Warning
If a URL displays the “Warning” status, it can indicate several things.
First, know that the Googlebot did index the page despite the warning. You will need to check the reasoning for the status of the report for greater details. The two types of warnings are as follows:
- Indexed, though blocked by robots.txt – Googlebot indexed the page despiting blocking it with your robots.txt file. This typically occurs when an external website is linking the blocked page. In this scenario, Googlebot still follows the outside link to the page and indexes it.
- Page indexed without content – Google was able to index the page, but some factor is preventing it from reading the actual content. You can refer to the coverage section of your report for more information.
How to Fix Warning Status Indexing Issues?
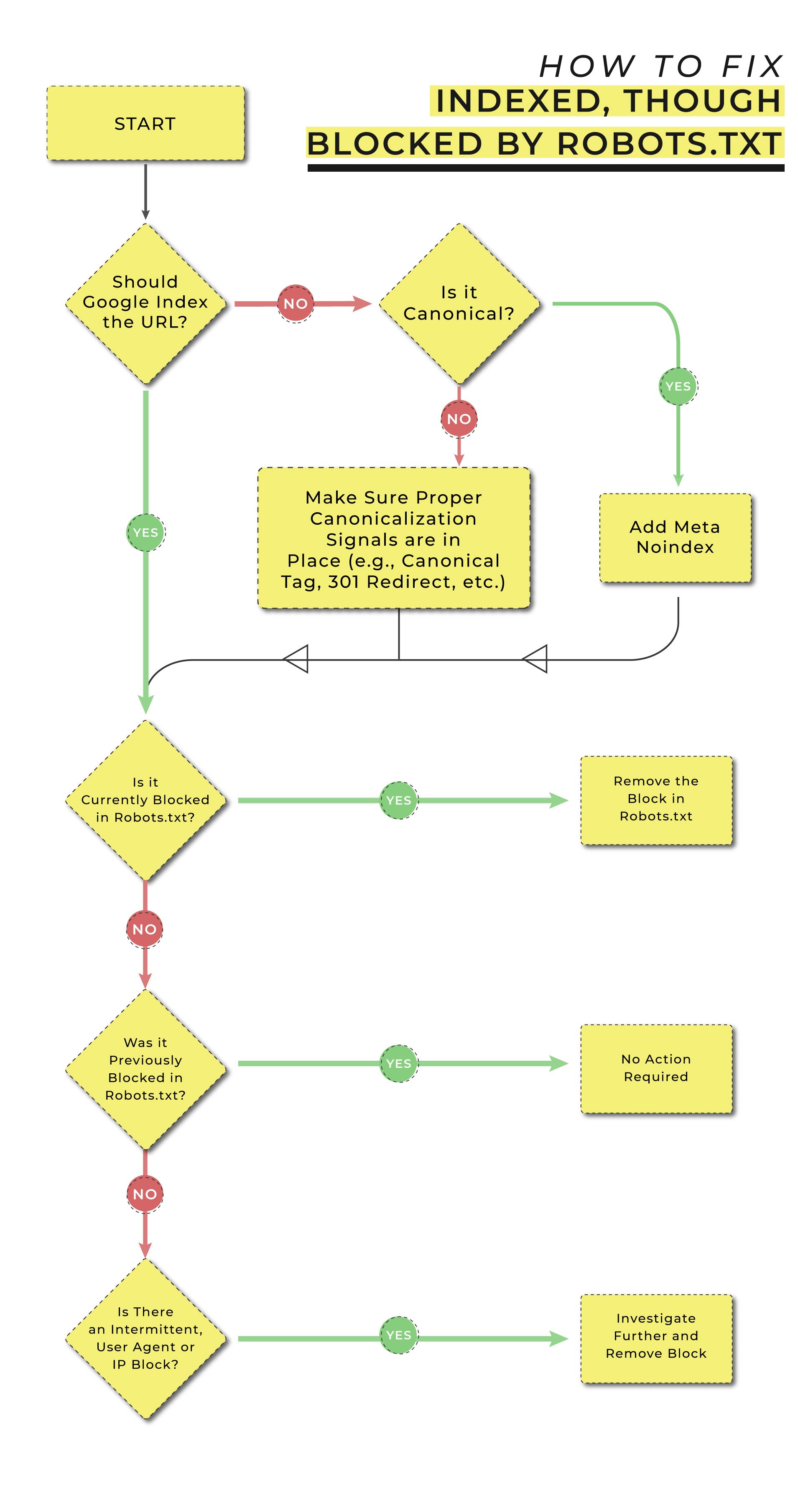
A. Indexed, Though Blocked by Robots.txt
If you intend to block the URL from further indexing, you must add a ‘noindex’ meta tag or header on the page for the HTTP response. Your meta tag should look like this:
<meta name=”robots” content=”noindex>
If you instead wish to add an HTTP response header, Google recommends the following:
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Furthermore, Google instructs us to not add the blocked URL to the robots.txt file. If you attempt to block using this method, Googlebot cannot check the page for the appropriate ‘noindex’ tag.
B. Page Indexed Without Content
This warning only occurs in rare circumstances. The most common culprit is accidentally publishing a webpage to your site that has zero content to read.
However, pages can also receive this warning if you are using a practice called cloaking.
Cloaking is the act of using technical processes to show Googlebot one type of content while showing your users something different than what is indexed. Cloaking is against Google guidelines and can prevent your website from appearing in any search results.
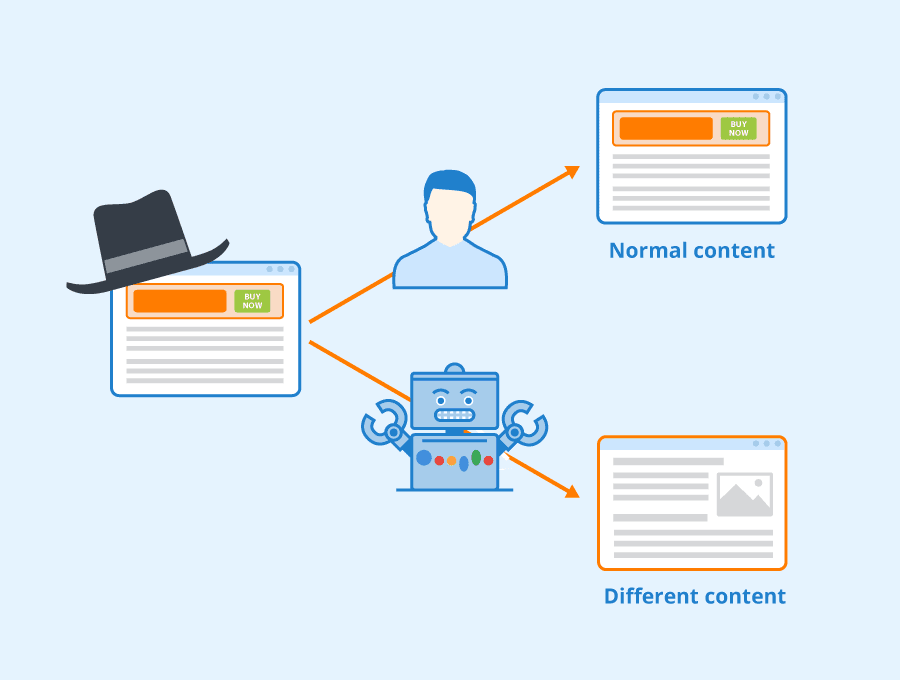
If you receive this warning, but cannot find a discernible cause, check with your development team for a possible hack. After addressing the problem, you can resubmit your website to Google for proper indexing.
Excluded
The ‘excluded’ response code typically appears by user choice.
Your SEO team may choose to prevent Googlebot from indexing a page for several reasons. The most common is having multiple versions of one page with duplicate content. To avoid penalties, you may exclude a page from the indexing process.
If you do not wish to exclude a URL, check your coverage report for one of the following messages:
- Excluded by ‘noindex’ tag – The URL has a meta tag or response code instructing Googlebot to avoid indexing the page.
- Blocked by page removal tool – An authorized website user blocked the URL with a URL removal request. These requests will expire after roughly 90 days.
- Blocked by robots.txt – A robots.txt file is blocking the indexing process.
- Blocked due to unauthorized request (401) – Googlebot was unable to continue the crawl after receiving a 401 authorization response put in place by the website owner.
- Crawled, currently not indexed – Googlebot crawled the page but has yet to index it. In most scenarios, the indexing will follow soon after.
- Discovered, currently not indexed – Googlebot identified the URL but stopped short of crawling to prevent site overload.
- Alternate page with proper canonical tag – Google recognizes this URL as a duplicate of an existing page. The other page has a canonical tag prompting it to avoid indexing.
- Duplicate without user-selected canonical – If two pages have duplicate content, and neither has a canonical tag, Googlebot will attempt to differentiate the two. This URL received the non-canonical tag.
- Duplicate, Google chose different canonical than user – Google sees your canonical tag but thinks this URL should be the one to receive the tag.
- Not found (404) – Googlebot found this URL organically only to receive a 404 error.
- Page with redirect – Googlebot will not index redirect URLs.
- Soft 404 – The URL leads to a page with a soft 404 not found message.
- Duplicate, submitted URL not selected as canonical – This URL is likely one of the multiple pages that contain duplicate content. However, none of these pages has the canonical tag.
- Blocked due to access forbidden (403) – The URL features restricted access prompting Googlebot to provide credentials. This almost always results in an incorrect error response on your site.
- Blocked due to other 4xx issue – This applies to an error caused by any other unnamed 4xx code.
How to Fix Excluded Status Indexing Issues?
1. Excluded by noindex' Tag
If you meant to use a noindex' tag, this code requires no response.
If you wish to submit the page for indexing, simply remove the noindex' tag from the page.
2. Blocked by Page Removal Tool
Avoid using URL removal requests and instead, use the robots.txt directive. Make additional attempts to crawl the URL for indexing before the request expires.
3. Blocked by Robots.txt
If you meant to block a URL from indexing, remove it from the robots.txt file and use the noindex' tag instead.
Otherwise, simply remove the URL from the robots.txt file.
4. Blocked Due to Unauthorized Request (401)
Remove the authorization requirements you have in place to access the page. More importantly, look into how this URL was discovered and address any related issues like broken or toxic links.
5. Crawled, Currently Not Indexed
Check the date of the last crawl. If it was recent, allow Google more time to index the page. Typically, no action is necessary.
6. Discovered, Currently Not Indexed
Google likely rescheduled the crawl. No action is necessary but check back to ensure that the site is properly indexed soon.
7. Alternate Page with Proper Canonical Tag
You added a canonical tag to a page with duplicate content. If this for some reason is incorrect, remove the canonical tag from the other URL and add it to the correct one.
8. Duplicate without User-Selected Canonical
Your site has more than one page with duplicate content. Select the most valuable one and add the canonical tag.
9. Not Found (404)
If the page no longer exists, meaning the 404 is intentional, no action is required.
If the page does exist at a new URL, you must add a redirect to the new location.
10. Page with Redirect
Google does not index redirects. No further action is necessary.
11. Soft 404
If the page no longer exists, make sure it returns a proper 404.
If you do not mean for a 404 to appear, you need to update this page with appropriate content for proper indexing.
12. Duplicate, Submitted URL Not Selected as Canonical
If you wish to index this as the URL, you will need to use the canonical tag. Google will index this page and prevent the other duplicates from being included.
13. Blocked Due to Access Forbidden (403)
If you wish to index this page, remove all restrictions preventing users and Googlebot from accessing the page.
If you intend for the page to be this way, be sure to utilize the noindex' tag as described earlier in this article.
14. Blocked Due to Other 4xx Issue
You will need to investigate the particular URL to understand its behavior. Be on the lookout for the 4xx status code and investigate what needs to be done to correct the issue. These errors range from 400 to 451, making it difficult to diagnose with a quick tutorial.
Error
The error code appears on your Coverage Report when Googlebot is unable to crawl the pages that are eligible for proper indexing.
The types of error codes are as follows:
- Server error (5xx) – This occurs when the website’s server is unable to fulfill the request to access the URL at the start of the process.
- Redirect error – One of a few direct errors occurred. This prevents Googlebot from reaching the desired URL for indexing.
- Submitted URL blocked by robots.txt – You blocked this page from indexing using your robots.txt file.
- Submitted URL marked ‘noindex’ – This occurs when you ask Google to index a page that has the ‘noindex’ tag.
- Submitted URL seems to be a Soft 404 – Googlebot crawled the page and found it to be a Soft 404.
- Submitted URL returns unauthorized request (401) – Authorization requirements prevented Google from crawling and indexing the page.
- Submitted URL not found (404) – You asked Google to index a URL that no longer exists.
- Submitted URL returned 403 – Something on the page is preventing anonymous users from gaining access. This is usually regarding a login issue.
- Submitted URL blocked due to other 4xx issue – One of the many 4xx response codes not previously listed prevents Google from indexing the URL.
How to Fix Error Status Indexing Issues?
1. Server Error (5xx)
5xx errors are most commonly a firewall issue. It can also be caused by a DoS protection protocol you have in place to prevent excessive requests to the server. Because Googlebot is making many requests in the indexing process, your security may be halting progress.
You or your hosting provider will need to examine which part of your website’s security is stopping Google. With the correct configurations, the indexing process should be allowed to go on without issue.
You can learn more about server errors from Google here.
2. Redirect Error
There are multiple types of redirect errors. The first step is to identify which one your website currently has.
- Redirect loop – Your redirect chain is taking the user back and forth between the same URLs. You need to check your redirect chain and make sure that the user ends up at the correct URL.
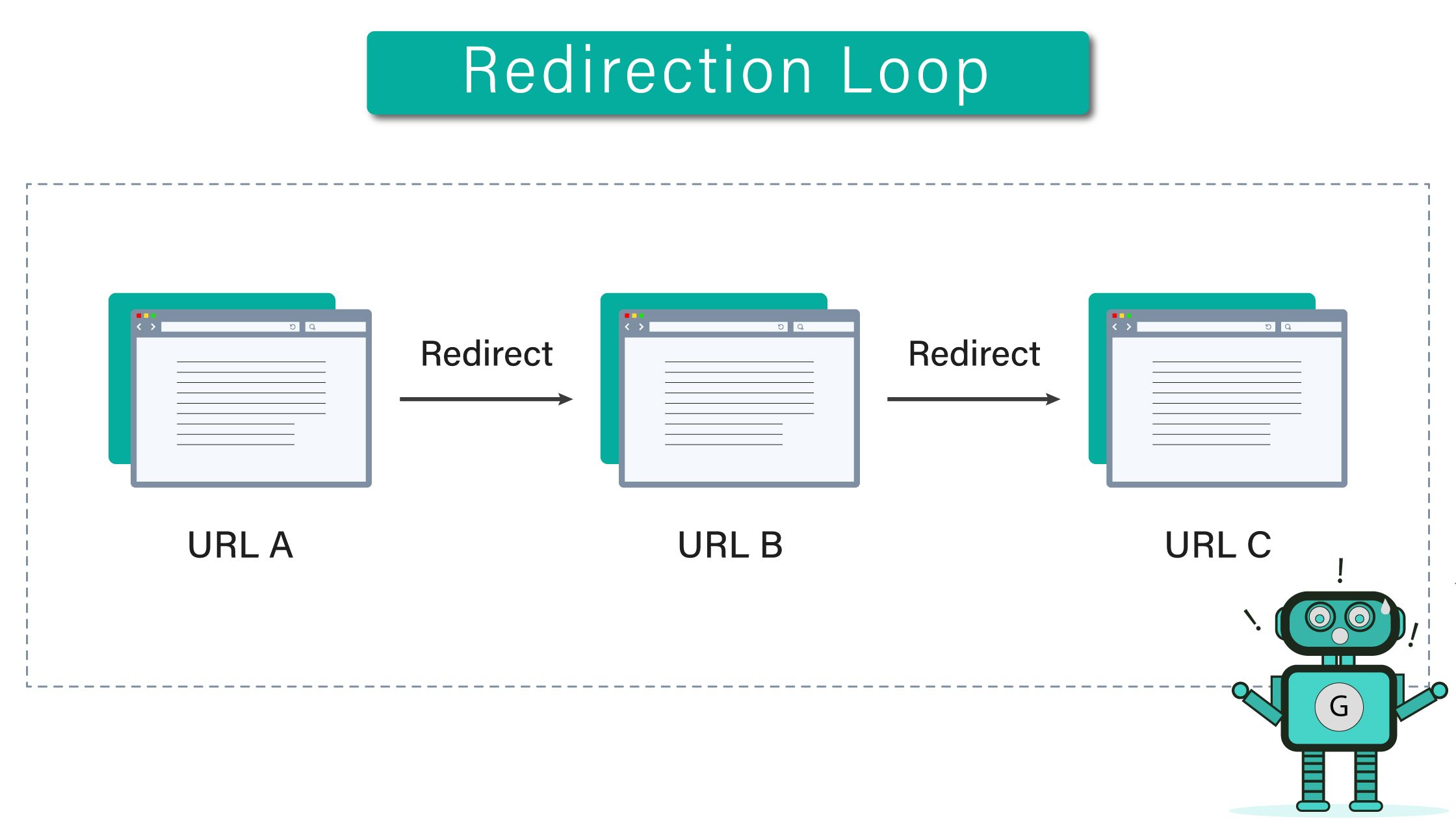
- Chain is too long – If you need to redirect users, you should always point them from URL A to URL B. If you receive this error, your website is redirecting Google too many times, causing it to abandon the crawl. Eliminate unnecessary steps in the chain to resume normally.
- Redirect URL exceeds max URL length – Google has a limitation on how many characters belong in a URL. If you receive this error, look into how you can update the URL or move the content to a new one.
- A bad or empty URL in the redirect chain - Google recognizes that one step in the chain is preventing normal navigation. Revisit your redirect protocol and make sure that each step points to the right destination.
If you have any more questions or concerns regarding redirects, Google recommends that website owners utilize Lighthouse for these types of errors.
3. Submitted URL Blocked by Robots.txt
If you wish to block a URL from indexing, you should not use robots.txt. Instead, use the noindex' protocol on the page.
If you mean for this page to be indexed, remove it from robots.txt and avoid using any unnecessary tags. Then, resubmit the URL for indexing.
4. Submitted URL Marked noindex'
If you wish to index this URL, you need to remove the noindex' protocol you have in place.
5. Submitted URL Seems to be a Soft 404
If you receive a soft 404 error, you can take one of the following actions depending on the situation.
If the page no longer exists, utilize a true 404 status code to indicate this.
If you moved the content to a new destination, submit the new page for indexing and remove the soft 404 page from the website.
6. Submitted URL Returns Unauthorized Request (401)
You must remove any authorization requirements if you want Googlebot to crawl the page.
7. Submitted URL Not Found (404)
You cannot submit a nonexistent URL for indexing.
If the content exists and you mistakenly used an old URL, update your sitemap with the correct URL.
8. Submitted URL Returned 403
Remove any restrictions that are preventing anonymous users from gaining access.
If you intended to restrict access, utilize the noindex' protocol for this URL.
9. Submitted URL Blocked Due to Other 4XX Issue
As we explained with similar exclusion errors, there are over 50 potential 4xx errors. Read the status description carefully to gain insight as to how you can correct the issue. See if you can replicate the issue or identify the problem using Google's URL inspection tool.
Address Index Coverage Issues Quickly to Protect Your Rankings
Google Search Console is a great boon for helping you publish your website updates quickly. The more you utilize best SEO practices, the more likely you are to see positive gains in SERPs.
Indexing issues are not uncommon. Fortunately, many of them are easily correctable with Google offering many solutions to get you back on track. Healthier websites equate to more satisfied users.
Understanding how Google responds to certain protocols also allows your SEO team to perform actions in your favor. This can protect your rankings as you experiment with website changes.
As long as you stay on top of these notifications, your website should always remain under control. Regardless of website length, utilizing these coverage reports will better serve you in keeping your website healthy.


.svg)




.svg)
.svg)
.svg)
.svg)
.svg)